

Big Data
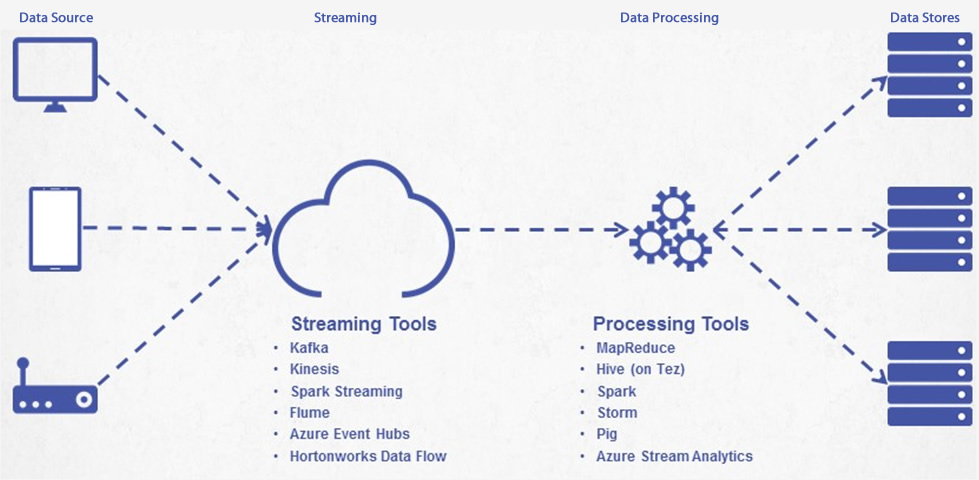
There are many different areas of the architecture to design when looking at a big data project. As data is being added to your Big Data repository, do you need to transform the data or match to other sources of disparate data? Can you handle the amount of data streaming into your Big data framework or can you mostly focus on processing the data coming in and pick the right data store or warehouse?
- STREAMING Ability to move large amounts of data by managing multiple parallel streams.
- DATA PROCESSING Perform many functions on the data prior to writing it to data stores. Need to run these tasks in parallel.
- DATA STORES Storage of data in relational and/or NoSQL data stores for business use in native form.
- DATA WAREHOUSING High speed tools for storing data in SQL Systems like Redshift.
- AWS SPARK and EMR – Insight360 has built a fast, reliable and reusable AWS framework for streaming and processing big data.
 Customer Data Platform
Customer Data Platform Insight360 Analytics
Insight360 Analytics Prospecting Insight
Prospecting Insight Sales Rep Insight
Sales Rep Insight Search Insight360
Search Insight360